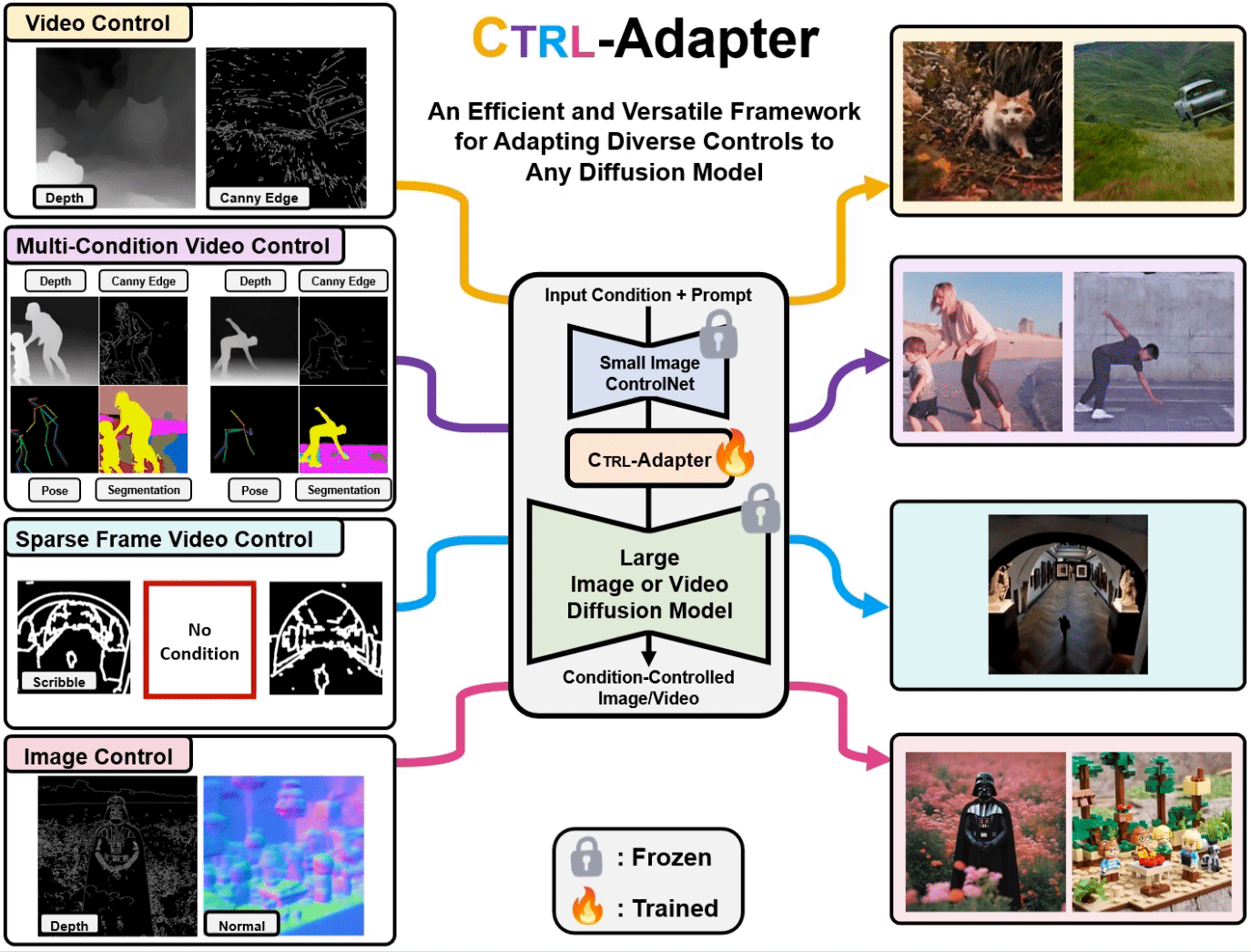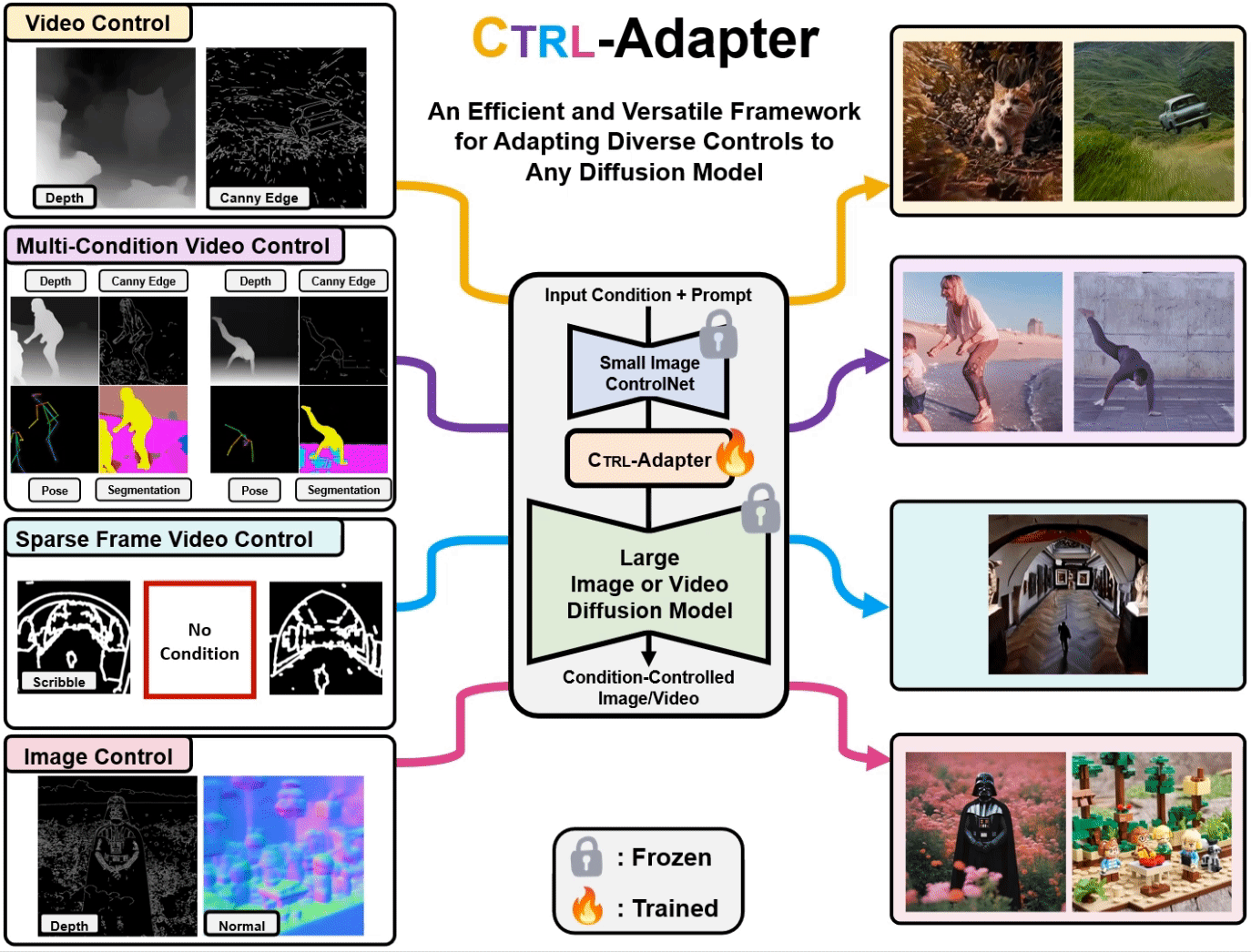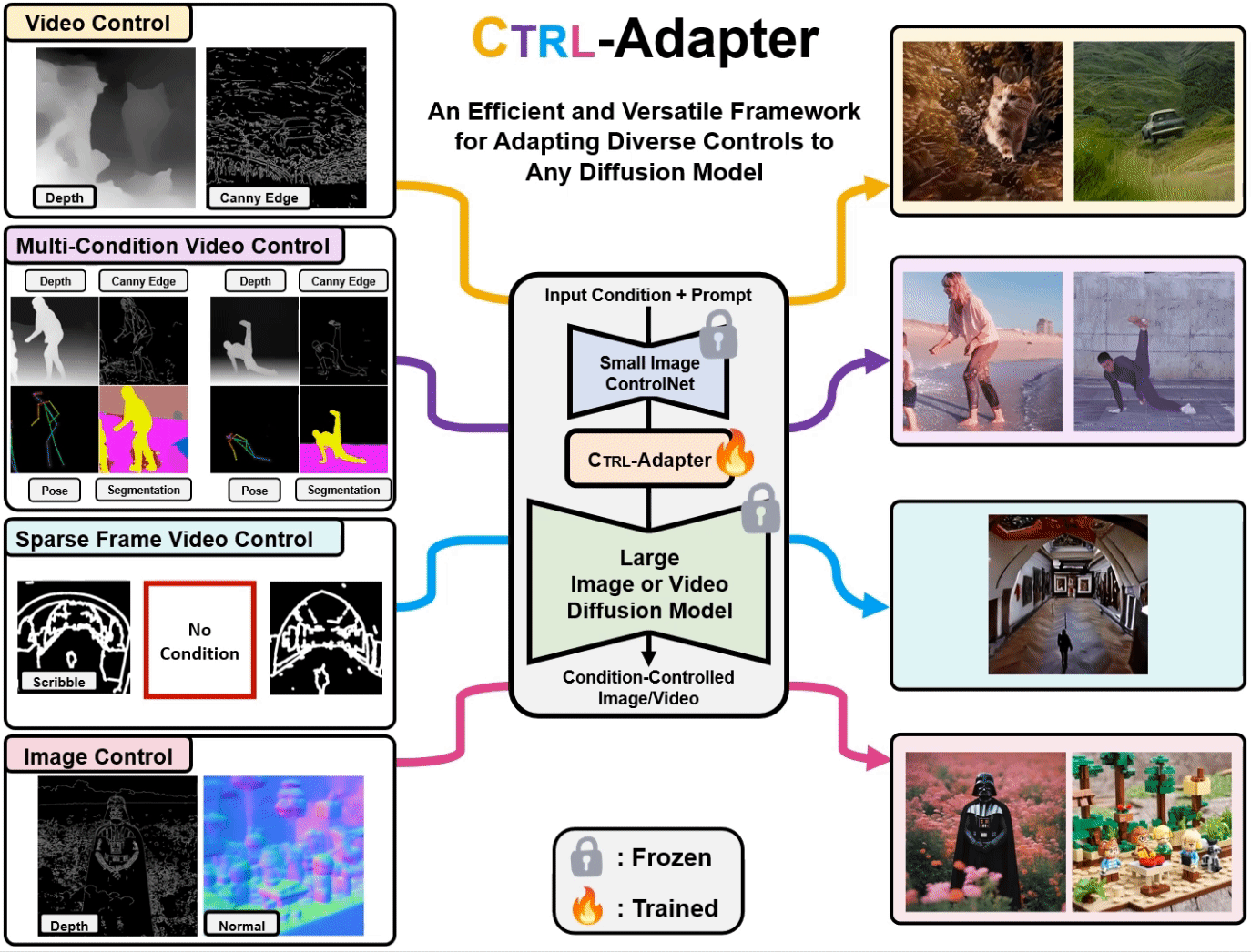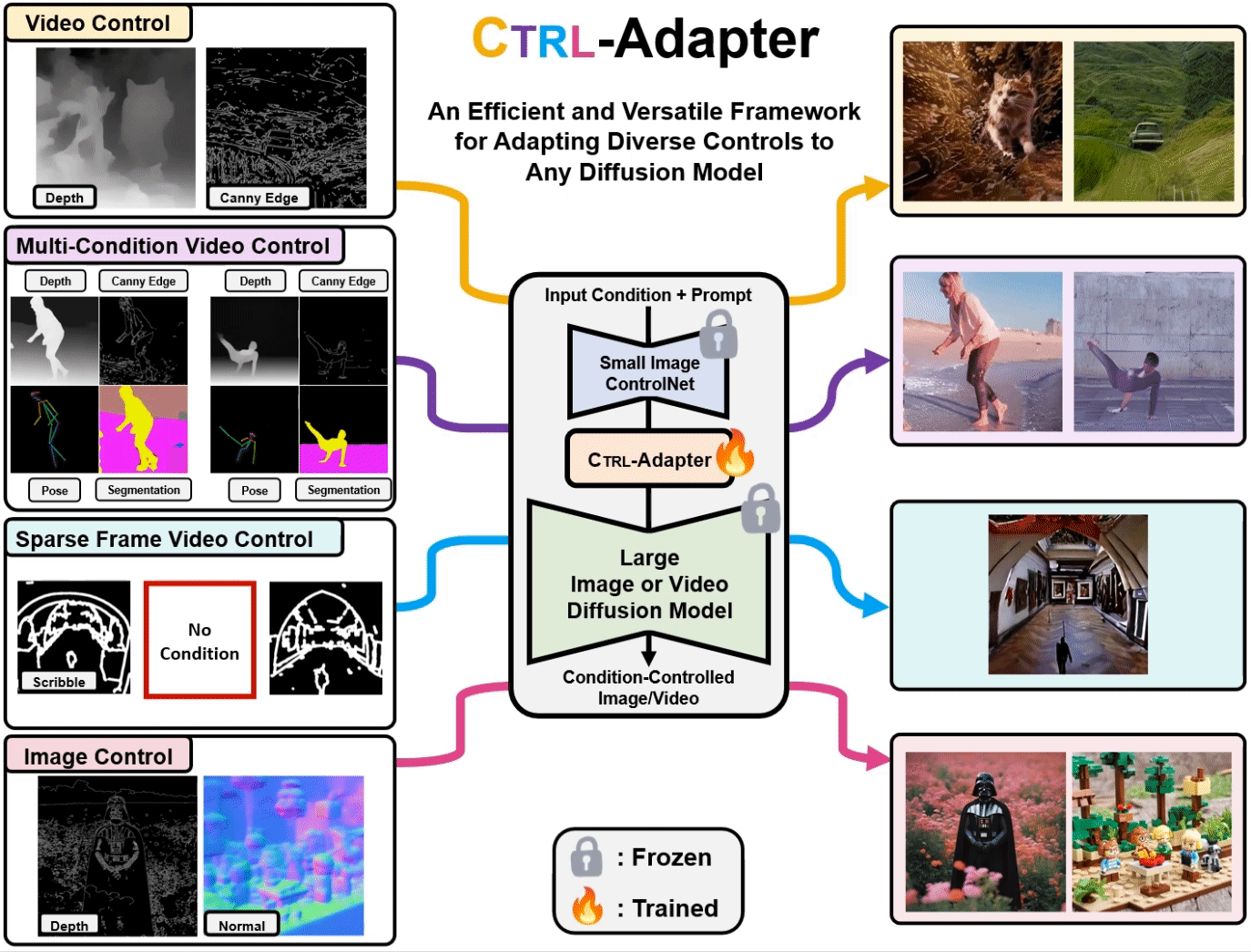
ControlNets are widely used for adding spatial control to text-to-image diffusion models with different conditions, such as depth maps, scribbles/sketches, and human poses. However, when it comes to controllable video generation, ControlNets cannot be directly integrated into new backbones due to feature space mismatches, and training ControlNets for new backbones can be a significant burden for many users. Furthermore, applying ControlNets independently to different frames cannot effectively maintain object temporal consistency.
To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion model through the adaptation of pretrained ControlNets. Ctrl-Adapter offers strong and diverse capabilities, including image and video control, sparse-frame video control, fine-grained patch-level multi-condition control (via an MoE router), zero-shot adaptation to unseen conditions, and supports a variety of downstream tasks beyond spatial control, including video editing, video style transfer, and text-guided motion control. With six diverse U-Net/DiT-based image/video diffusion models (SDXL, PixArt-α, I2VGen-XL, SVD, Latte, Hotshot-XL), Ctrl-Adapter matches the performance of pretrained ControlNets on COCO and achieves the state-of-the-art on DAVIS 2017 with significantly lower computation (< 10 GPU hours).
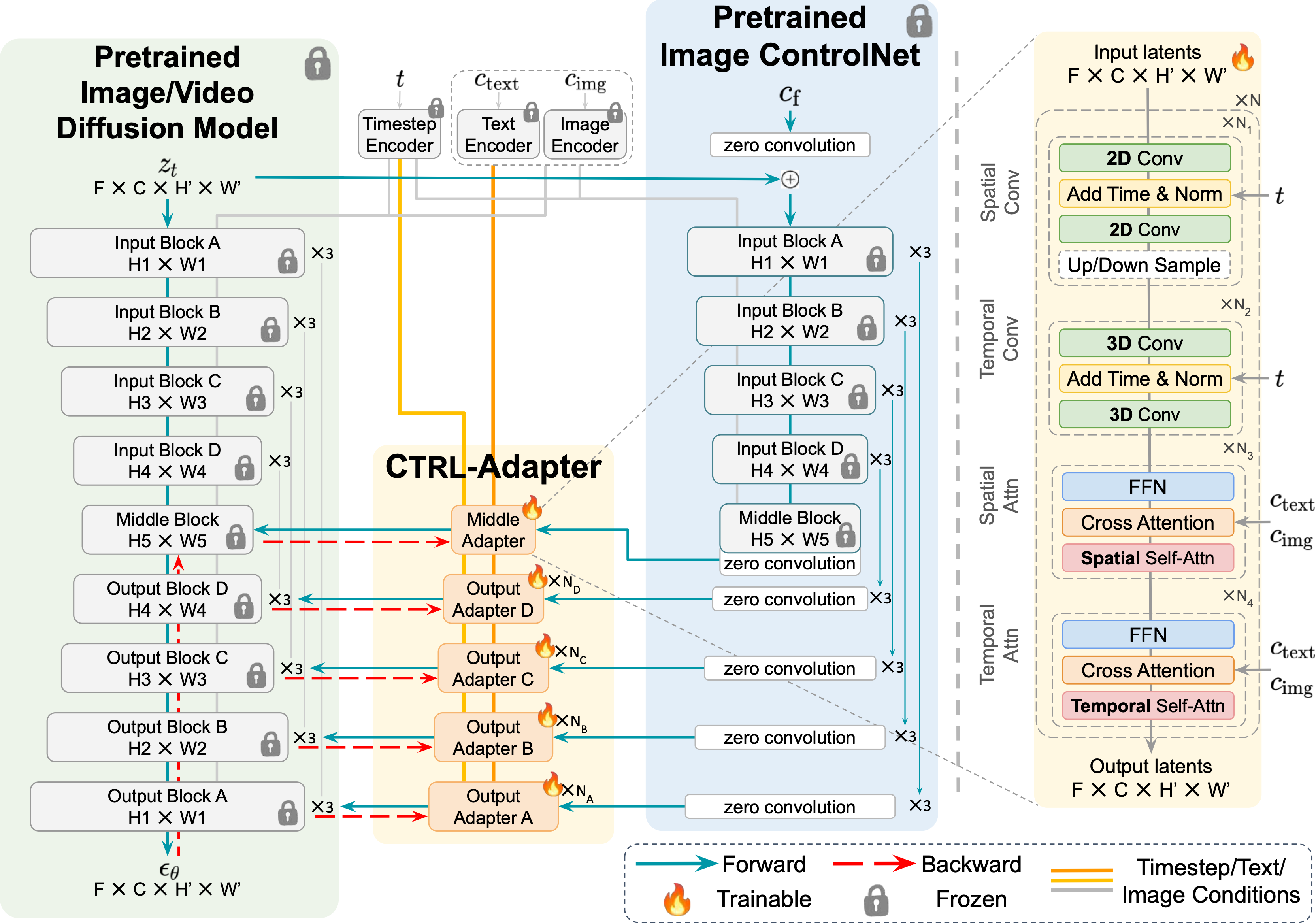
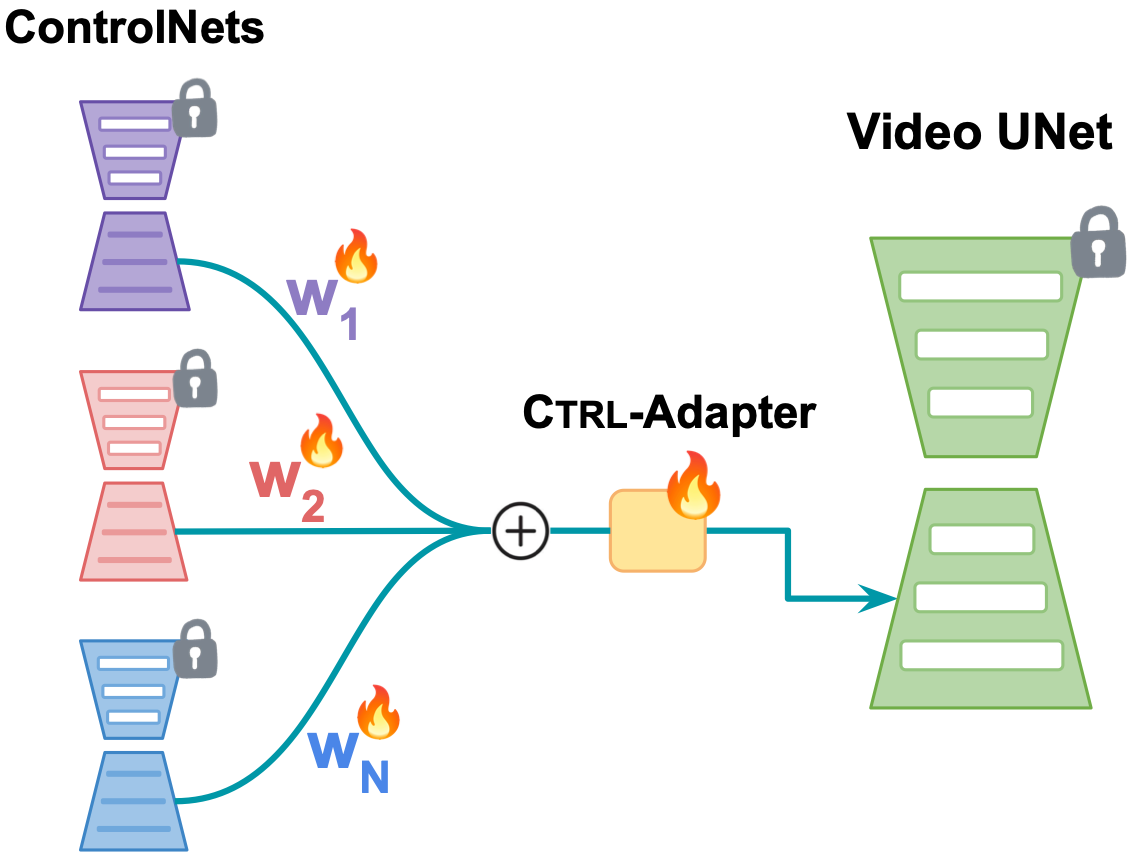
Efficient Adaptation of Pretrained ControlNets. As shown in the left figure, we train an adapter module (colored orange) to map the middle/output blocks of a pretrained ControlNet (colored blue) to the corresponding middle/output blocks of the target video diffusion model (colored green). We keep all parameters in both the ControlNet and the target video diffusion model frozen. Therefore, training a Ctrl-Adapter can be significantly more efficient than training a new video ControlNet.
Ctrl-Adapter architecture. As shown in the right figure, each block of Ctrl-Adapter consists of four modules: spatial convolution, temporal convolution, spatial attention, and temporal attention. The temporal convolution and attention modules model effectively fuse the in ControlNet features for better temporal consistency. When adapting to image diffusion models, Ctrl-Adapter blocks only consist of spatial convolution/attention modules (without temporal convolution/attention modules).
We show examples from both U-Net based models (I2V-GenXL & SDXL), and DiT based models (Latte & Pixart-α)

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|

|

| Control | Generated Video | |
|---|---|---|

|
|
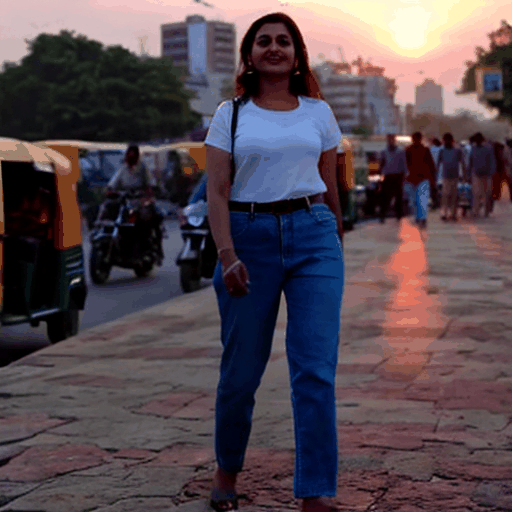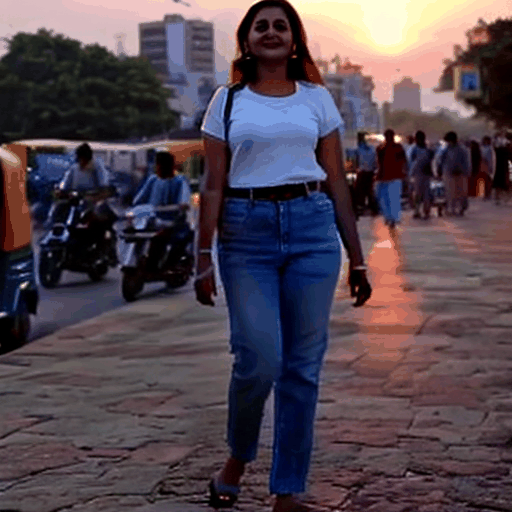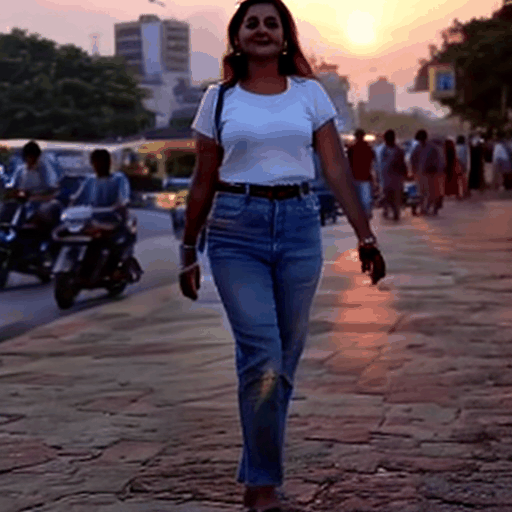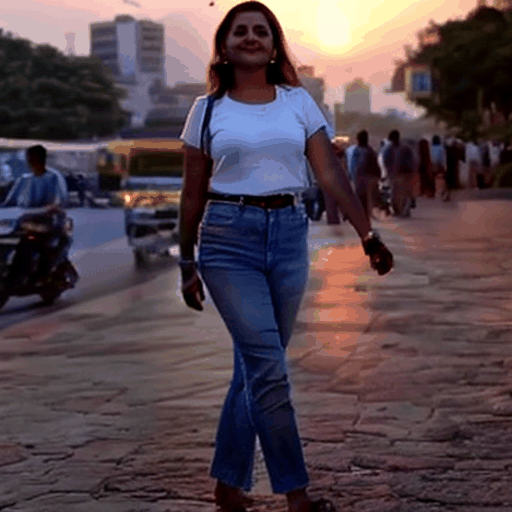
|
| Control | Generated Video | |
|---|---|---|
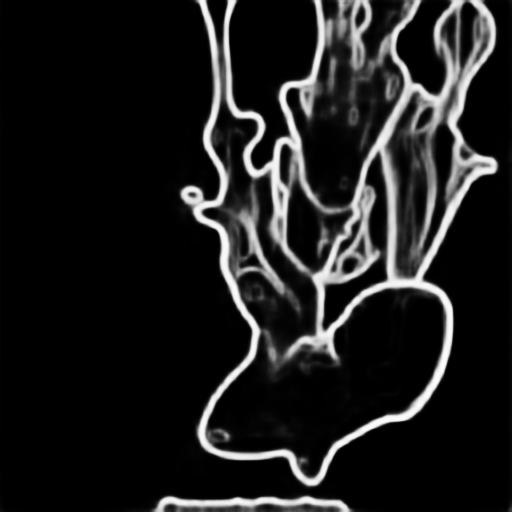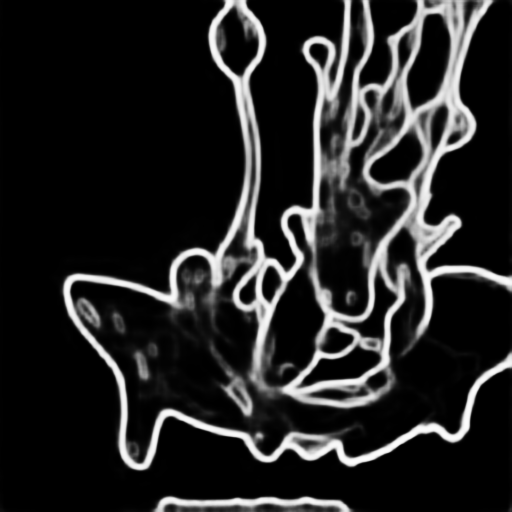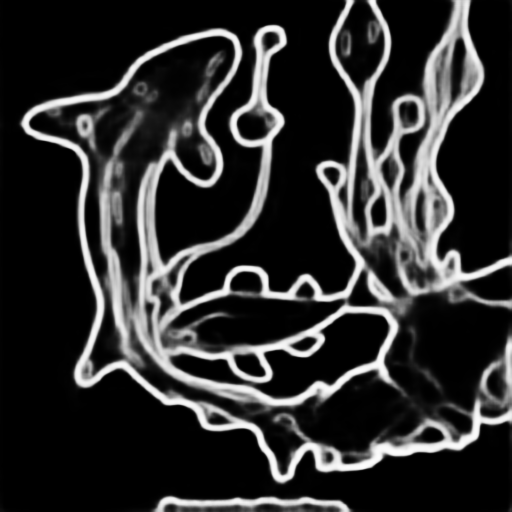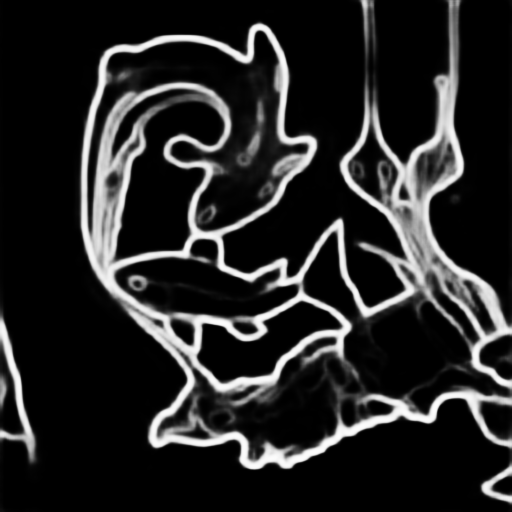
|
|

|
| Control | Generated Video | |
|---|---|---|

|
|

|
| Control | Generated Video | |
|---|---|---|

|
|

|

| Controls | Generated Video | |
|---|---|---|


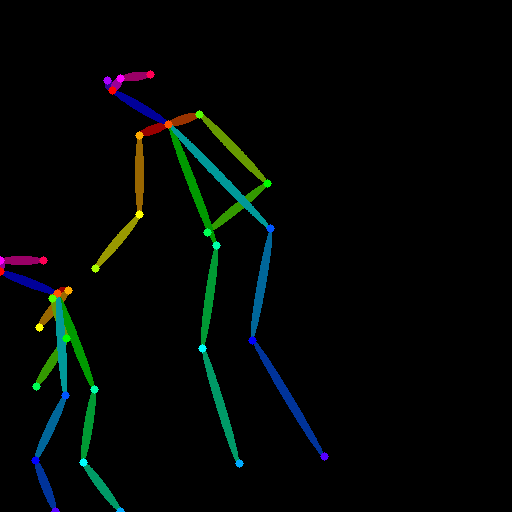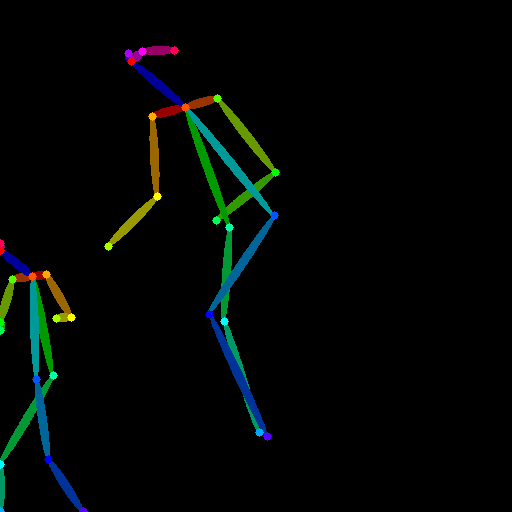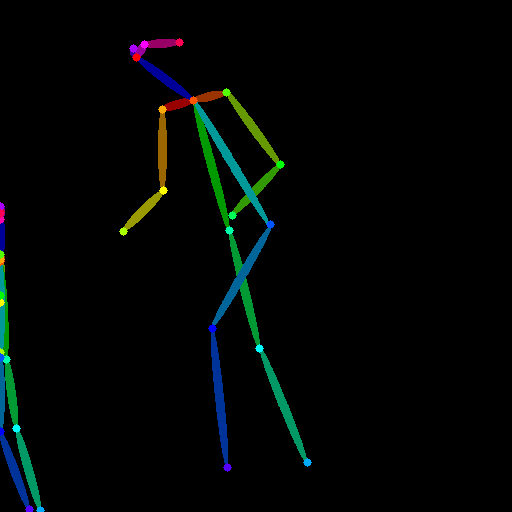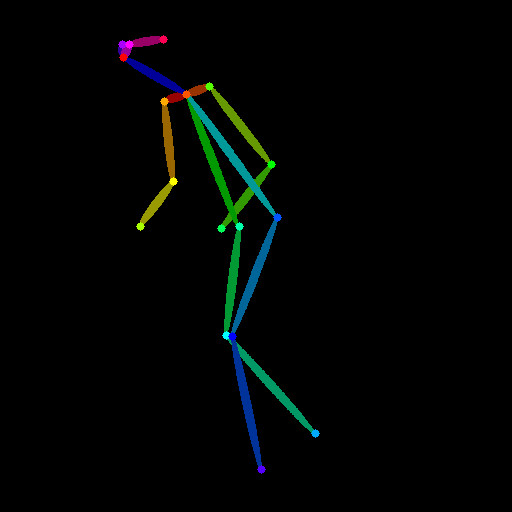

|
|

|

| Controls | Generated Video | |
|---|---|---|

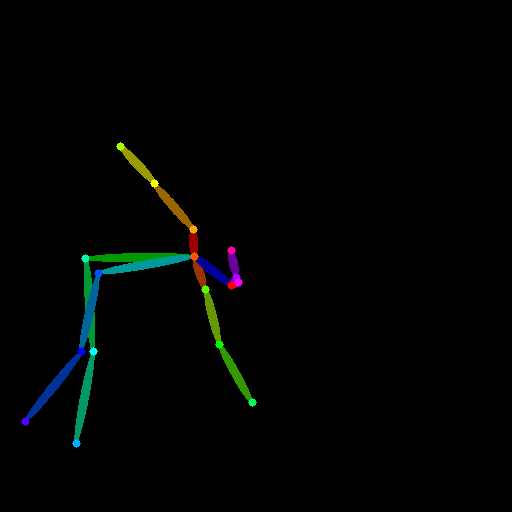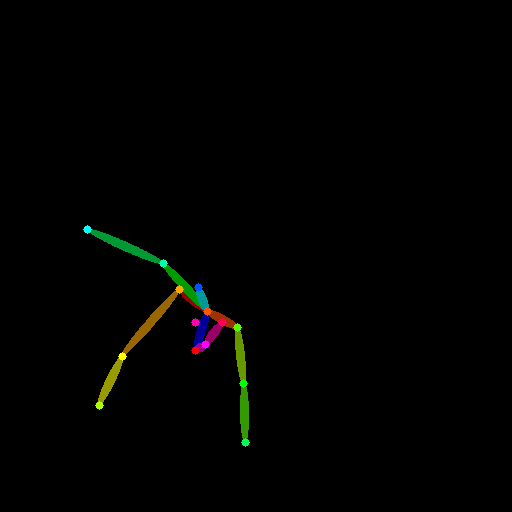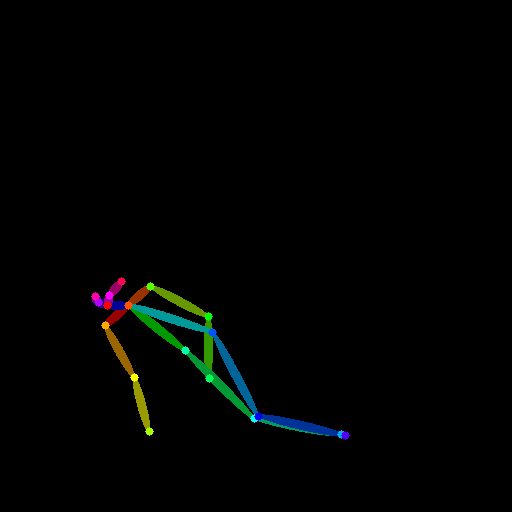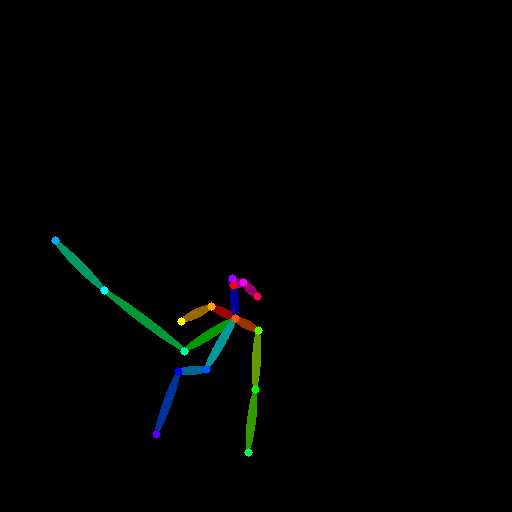
|
|

|

| Controls | Generated Video | |
|---|---|---|



|
|

|

| Controls | Generated Video | |
|---|---|---|


|
|

|
(1) Control Condition Extraction


| Input Prompt | (2) Generated Frame (Generated by SDXL + Ctrl-Adapter) |
(3) Generated Video (Generated by I2VGen-XL + Ctrl-Adapter) |
|||
|---|---|---|---|---|---|

|
A camel with rainbow fur walking. |
|

|
|

|
|
|
A zebra stripped camel walking. |
|

|
|

|
|
|
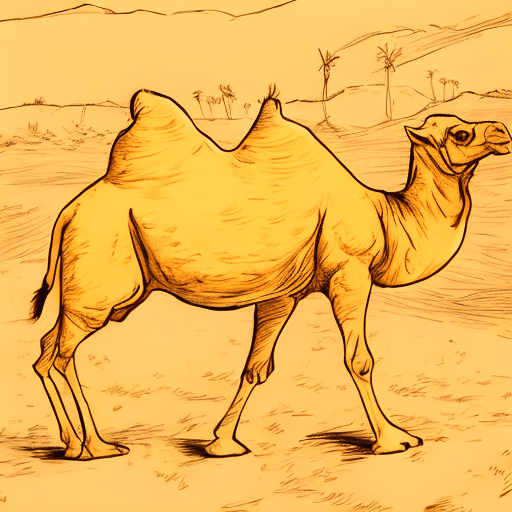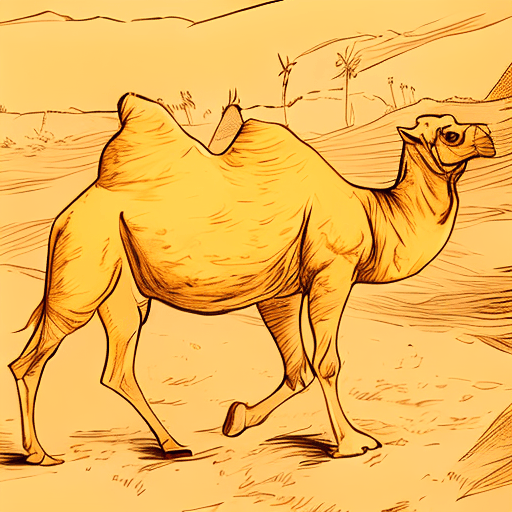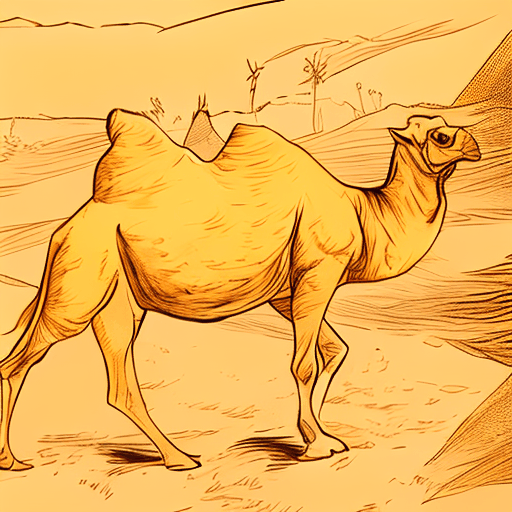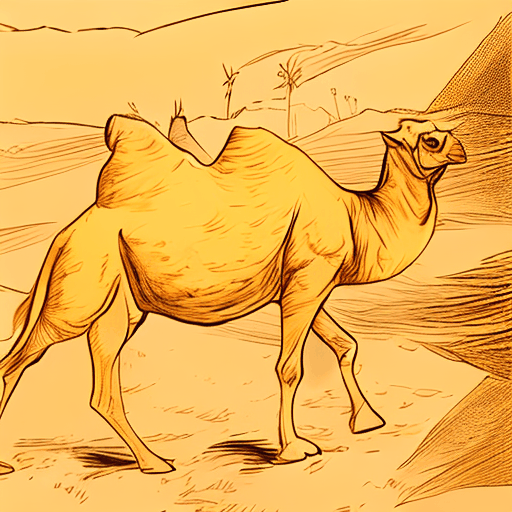
A camel walking, ink sketch style. |
|

|
|
|
|
|
A camel walking, van gogh-style. |
|

|
|

|
| Initial Frame | Object Masking | Input Prompt | Generated Video (Generated by I2VGen-XL + Ctrl-Adapter) |
|||
|---|---|---|---|---|---|---|

|
|

|
|
A white and orange tabby alley cat is seen darting across a back street alley in a heavy rain, looking for shelter. |
|

|

|
|

|
|
A white and orange tabby cat is darting through a dense garden, as if chasing something |
|

|

|
|

|
|
An elk with impressive antlers grazing on the snow-covered ground |
|

|
| Initial Frame | Shuffled | Input Prompt | Generated Video (Generated by I2VGen-XL + Ctrl-Adapter) |
|||
|---|---|---|---|---|---|---|

|
|

|
|
A miniature Christmas village with snow-covered houses, glowing windows, decorated trees, festive snowmen, and tiny figurines in a quaint, holiday-themed diorama evoking a cozy, celebratory winter atmosphere |
|

|

|
|

|
|
Stop motion of a colorful paper flower blooming |
|

|

|
|

|
|
Beautiful, snowy Tokyo city is bustling |
|

|

| Sparse Inputs (Condition is given for 4 out of 16 frames) |
Generated Video | |
|---|---|---|

 ...
...
|
|

|

| Sparse Inputs (Condition is given for 4 out of 16 frames) |
Generated Video | |
|---|---|---|
 ...
...

|
|

|

| Condition | Controls | Generated Video | |
|---|---|---|---|
|
Training: Depth Map Inference: Normal Map |

|
|

|

| Condition | Controls | Generated Video | |
|---|---|---|---|
|
Training: Depth Map Inference: Line art |

|
|

|

| Condition | Controls | Generated Video | |
|---|---|---|---|
|
Training: Depth Map Inference: Softedge |

|
|

|
| Prompt | Control | Generated Image | |
|---|---|---|---|
|
Cute fluffy corgi dog in the city in anime style |

|
|

|
|
happy Hulk standing in a beautiful field of flowers, colorful flowers everywhere, perfect lighting, leica summicron 35mm f2.0, Kodak Portra 400, film grain |

|
|

|
|
Astronaut walking on water |

|
|

|
|
a cute mouse pilot wearing aviator goggles, unreal engine render, 8k |

|
|

|
|
Cute lady frog in dress and crown dressed in gown in cinematic environment |

|
|

|
|
A cute sheep with rainbow fur, photo |

|
|

|
|
Cute and super adorable mouse in black and red chef coat and chef hat, holding a steaming entree |

|
|

|
|
a cute, happy hedgehog taking a bite from a piece of watermelon, eyes closed, cute ink sketch style illustration |

|
|

|
| Prompt | Control | Generated Image | |
|---|---|---|---|
|
A plate of cheesecake, pink flowers everywhere, cinematic lighting, food photography |

|
|

|
|
Darth Vader in a beautiful field of flowers, colorful flowers everywhere, perfect lighting |

|
|

|
|
A micro-tiny clay pot full of dirt with a beautiful daisy planted in it, shining in the autumn sun |

|
|

|
|
A raccoon family having a nice meal, life-like |

|
|

|
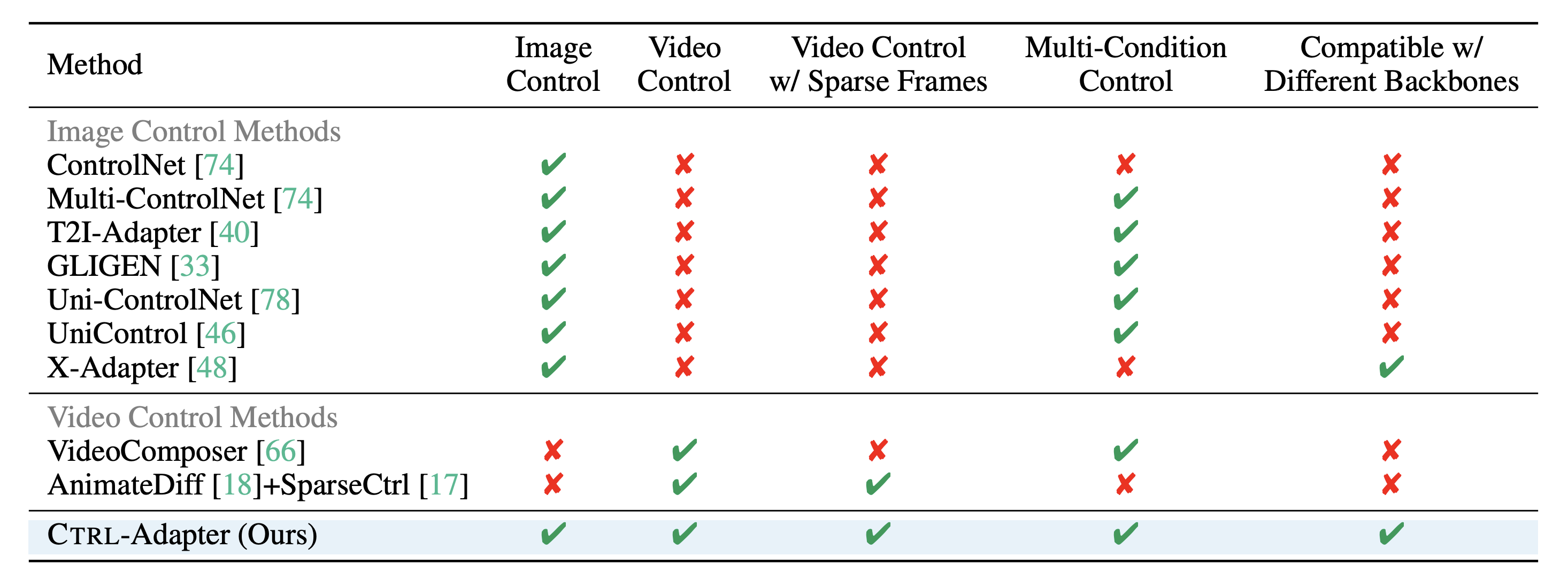
Overview of the capabilities supported by recent methods for controlled image/video generation. Ctrl-Adapter supports diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbone models, while previous methods support only support a small subset of them.
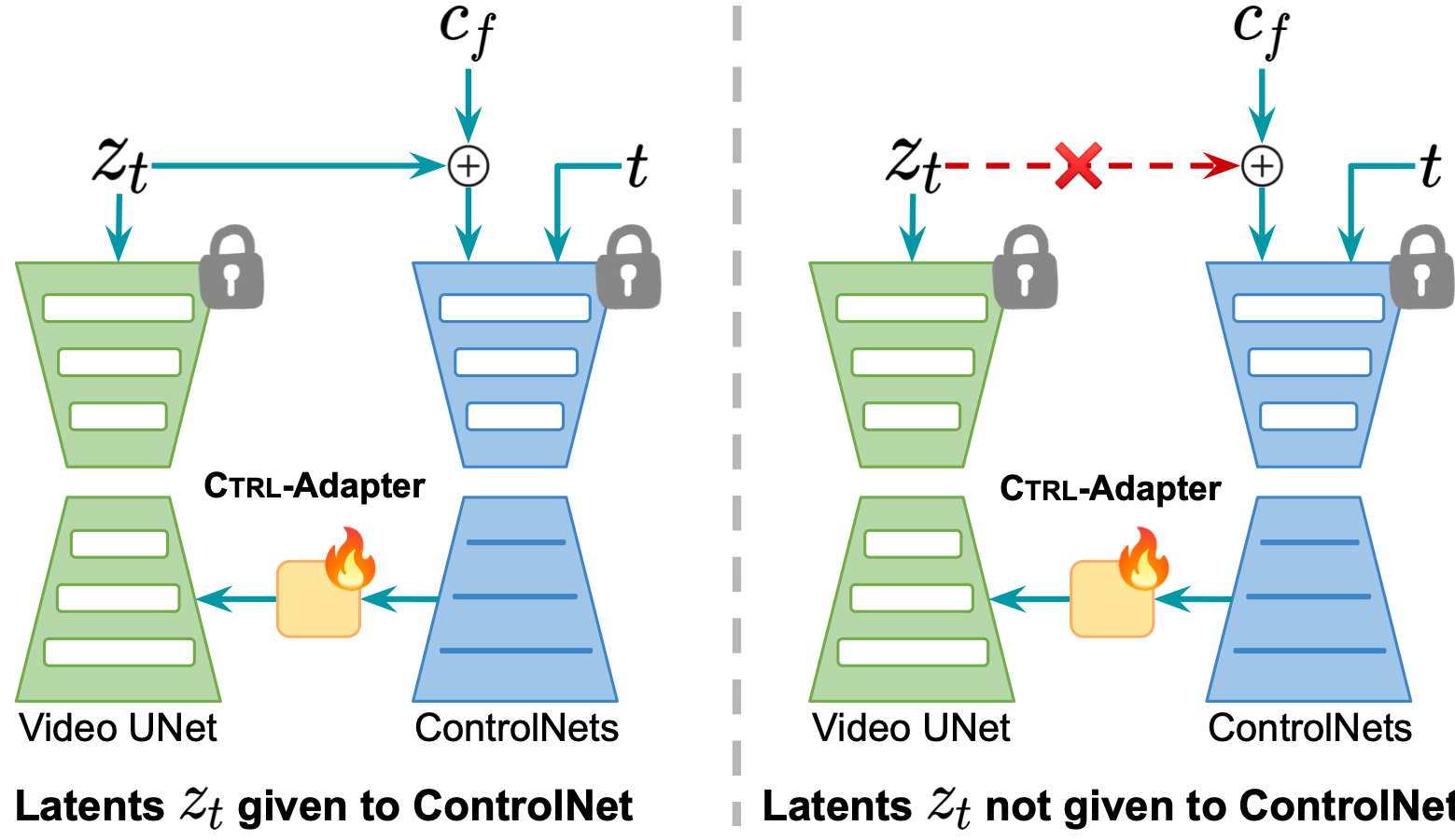
Although the original ControlNets take the latent as part of their inputs, we find that skipping from ControlNet inputs is effective for Ctrl-Adapter when (1) adpating to backbones diffusion models with different noise scales and (2) video generation with sparse frame conditions (i.e., conditions are only provided for the subset of video frames).
For more effective spatial control beyond a single condition, we can easily combine the control features of multiple ControlNets via Ctrl-Adapter. For this, we propose a lightweight mixture-of-experts (MoE) router that takes patch-level inputs and assigns weights to each condition. In our experiments, we find that our MoE router is more effective than equal weights or unconditinoal global weights.
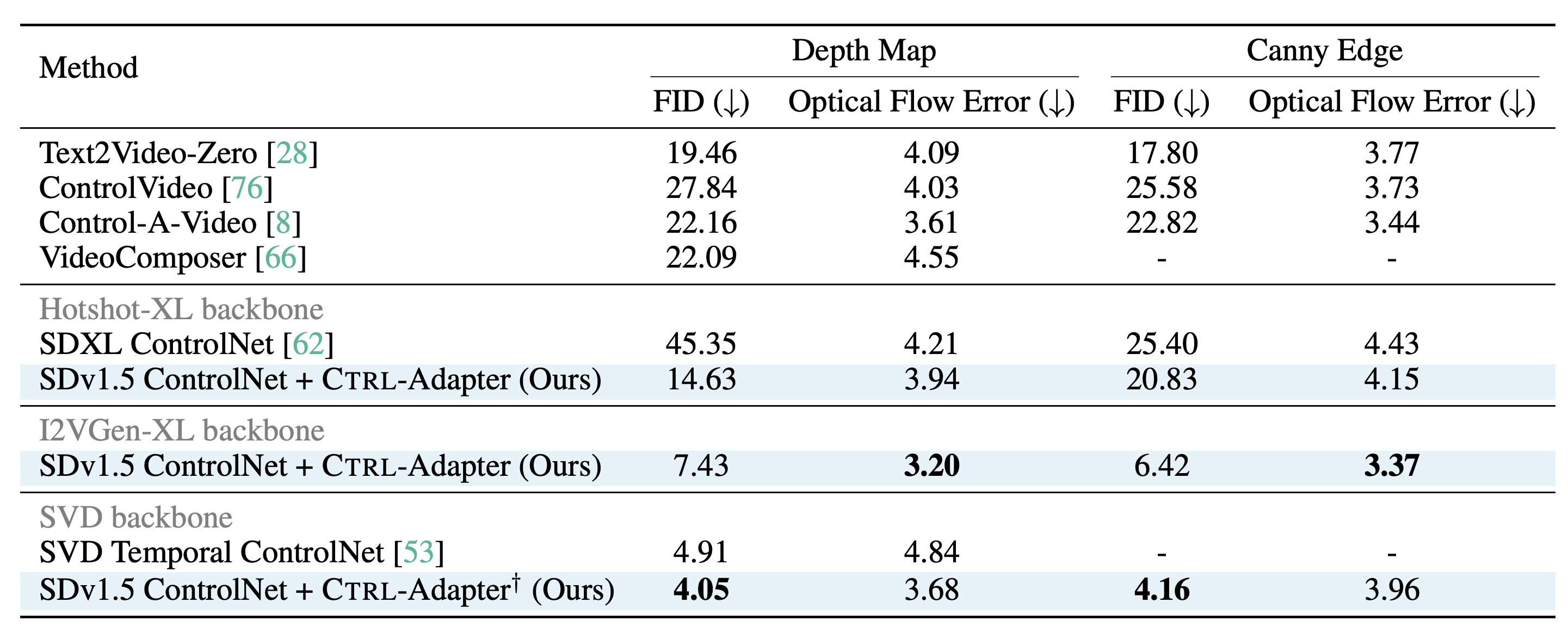
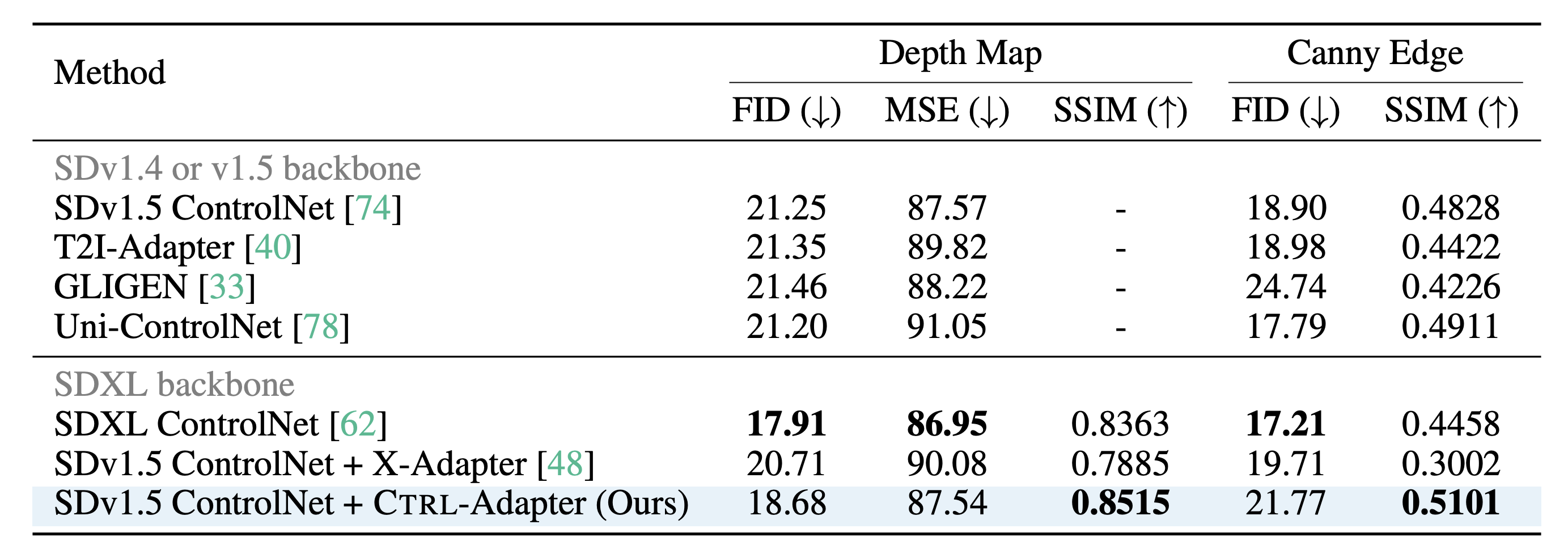
Left: Evaluation on video control with a single condition on DAVIS 2017 dataset. Right: Evaluation on image control with a single condition on COCO dataset. We demonstrate that Ctrl-Adapter matches the performance of a pretrained image ControlNet and outperforms previous methods in controllable video generation (achieving state-of-the-art performance on the DAVIS 2017 dataset) with significantly lower computational costs (Ctrl-Adapter outperforms baselines in less than 10 GPU hours).
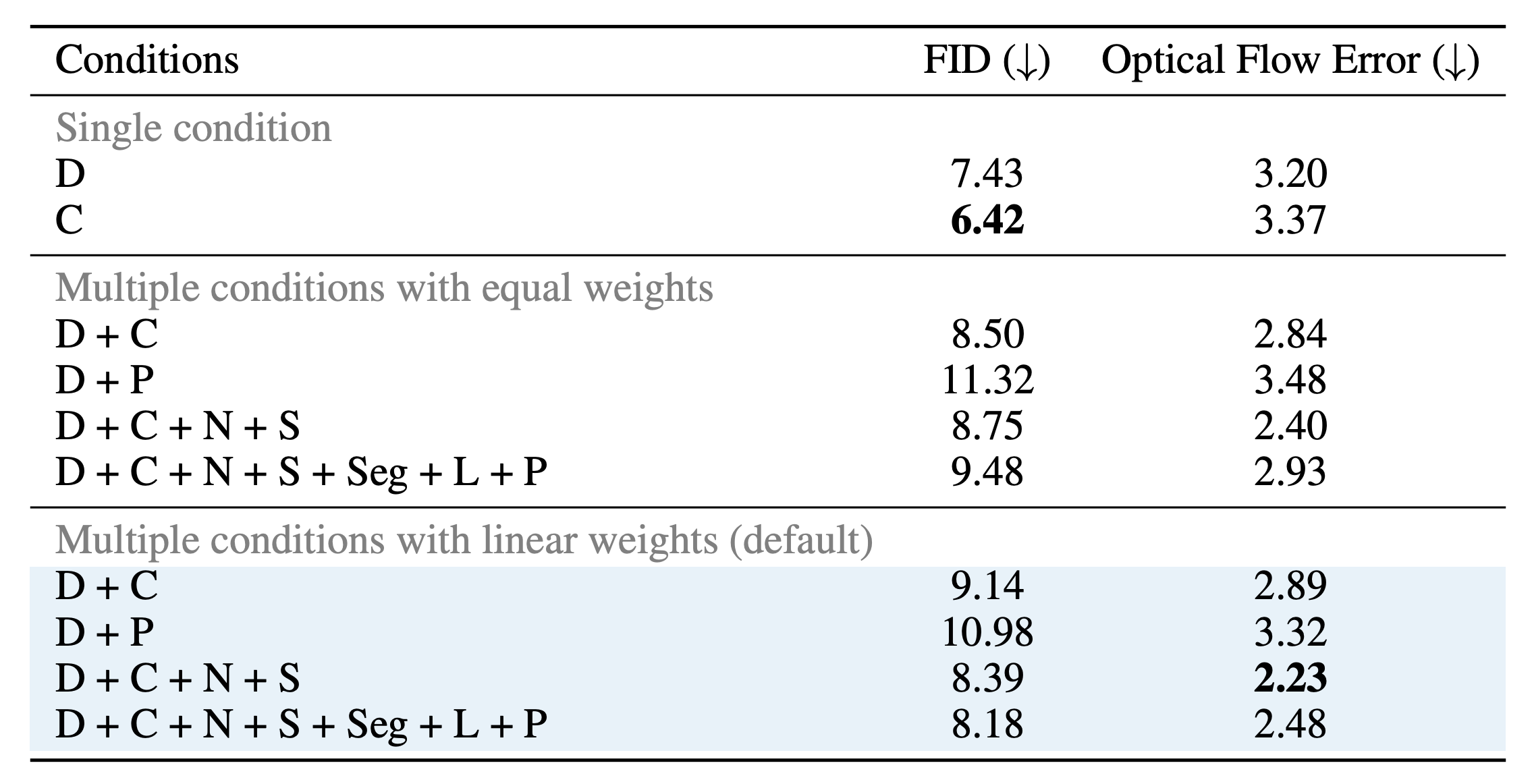
More conditions improve spatial control in video generation. The proposed patch-level weighting method outperforms the equal-weight approach and unconditional global weighting. The control sources are abbreviated as D (depth map), C (canny edge), N (surface normal), S (softedge), Seg (semantic segmentation map), L (line art), and P (human pose).
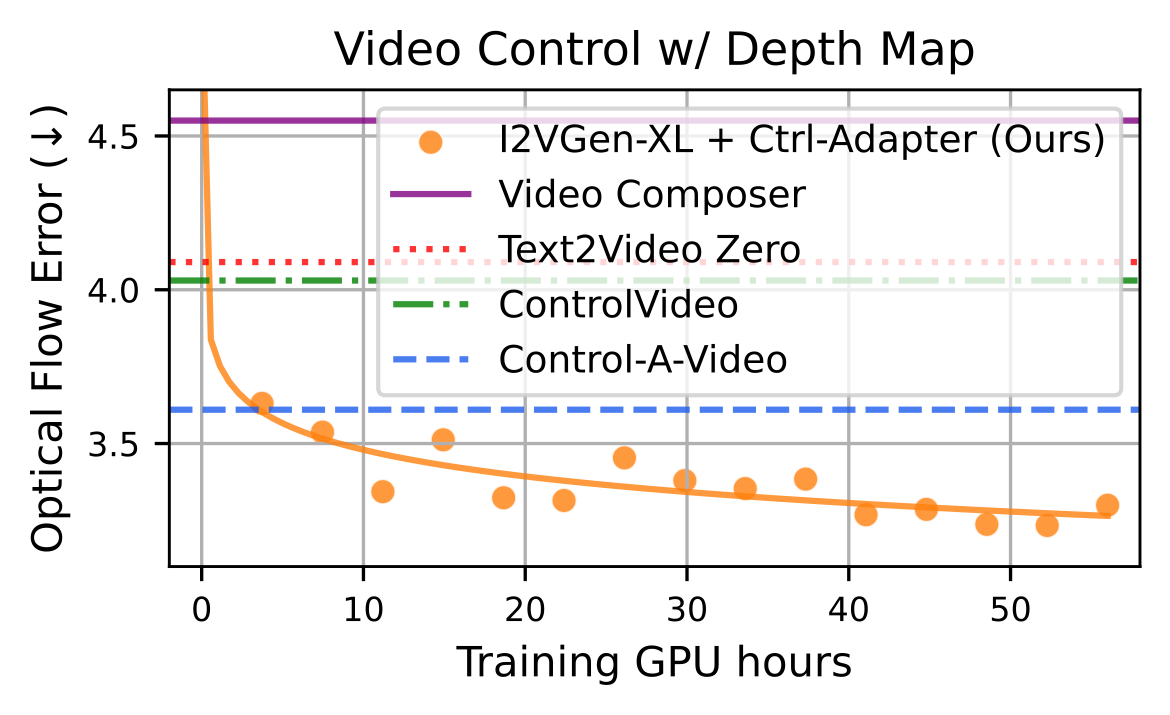
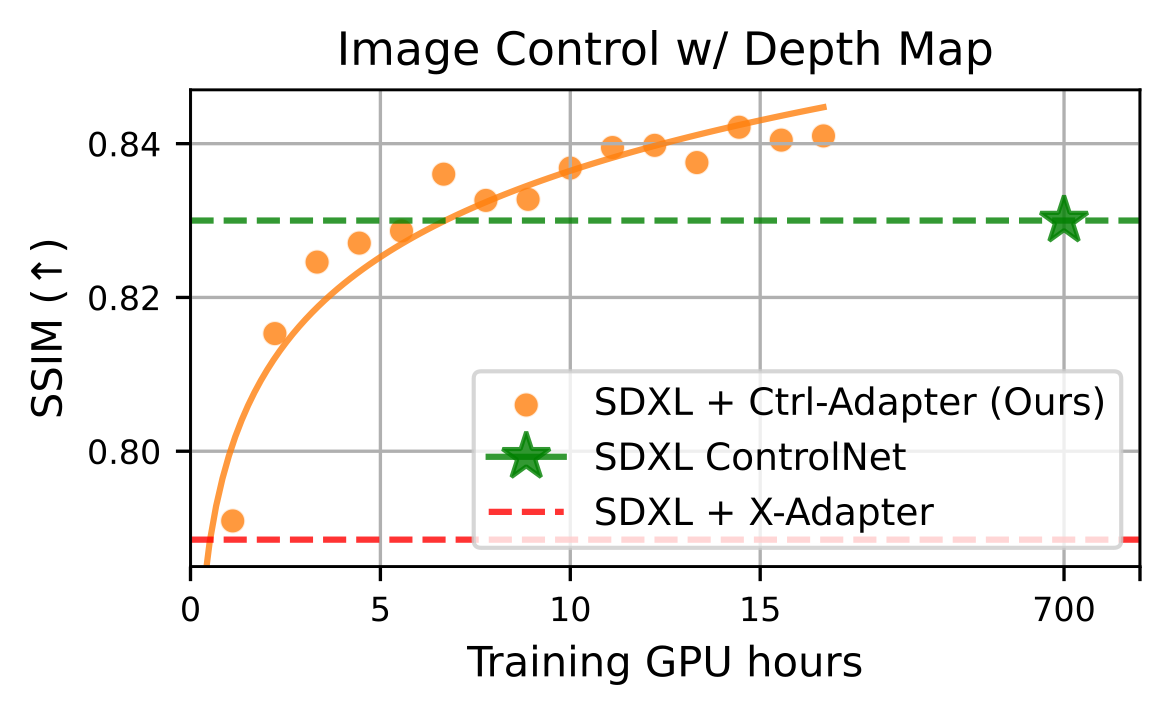
Training speed of Ctrl-Adapter for video (left) and image (right) control with depth map. The training GPU hours are measured with A100 80GB GPUs. For both video and image controls, Ctrl-Adapter outperforms strong baselines in less than 10 GPU hours.
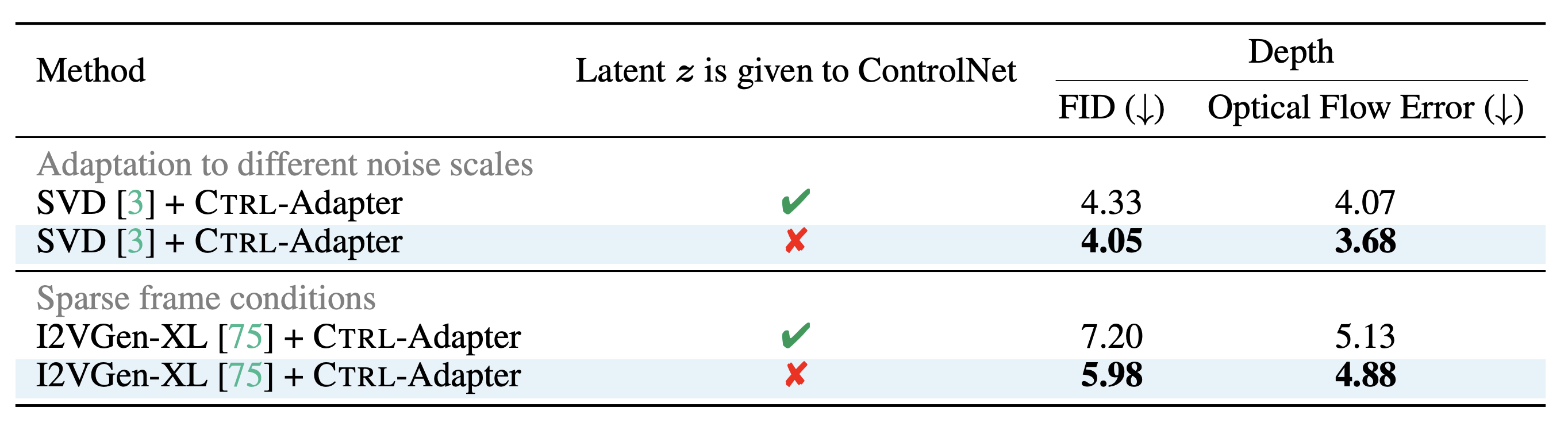
We find that skipping the latents from ControlNet inputs helps Ctrl-Adapter for (1) adaptation to backbone models with different noise scales and (2) video control with sparse frame conditions.
Our framework is primarily for research purposes (and therefore should be used with caution in real-world applications).
Note that the performance/quality/visual artifacts of Ctrl-Adapter largely depend on the capabilities (e.g., motion styles and video length) of the current open-source backbone video/image diffusion models used.
@article{Lin2024CtrlAdapter,
author = {Han Lin and Jaemin Cho and Abhay Zala and Mohit Bansal},
title = {Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model},
year = {2024},
}